很久没有用到进程池,今天公司项目需要大量进程,考虑使用进程池操作。其实很简单,几行代码就可以搞定,但是遇到了一个比较有意思的问题。之前写Python都是在Linux上,没有出现过,今天发现Windows上还是有一些区别。
我以为很简单,导包,创建,使用,结束。五行搞定。
from multiprocessing import Pool
pool = mp.Pool(processes=mp.cpu_count())
pool.map(__opFunc, dataList)
pool.close()
pool.join()然后就悲剧的报错了:
PicklingError: Can't pickle <type 'function'>: attribute lookup builtin.function failed
开始有点蒙,测试一下吧。。。我的测试代码:
from multiprocessing import Pool
def func(num):
res = num * num
print(res)
l = range(1, 60)
pool = Pool(processes=20)
r = pool.map(func, l)
pool.close()
pool.join()看一下报错:
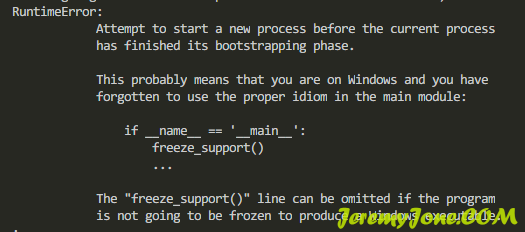
报了一个 freeze_support()的错误,提示信息也很明显,告诉我们需要主进程,而且还提示我们很可能在Windows下进行操作,看来还是比较清晰的问题。
既然知道了错误,添加一个主进程即可。
from multiprocessing import Pool
def func(num):
res = num * num
print(res)
l = range(1, 60)
if __name__ == "__main__":
pool = Pool(processes=20)
r = pool.map(func, l)
pool.close()
pool.join()这样就可以了。
测试通过了,也就发现项目中的问题错在哪里,开始我把__opFunc定义在了函数内部,只需要将map中的函数放在模块顶级即可,即模块顶级函数。
def __opFunc(data):
# handle
# ...
def opFunc(dataList):
# Create process pool, process count is cpu count
pool = mp.Pool(processes=mp.cpu_count())
pool.map(__opFunc, dataList)
# Need to wait finish.
pool.close()
pool.join()在其他地方调用opFunc函数即可。
引起这个问题的,是进程池的工作方式:
- 池使用FIFO调度将任务分配给可用的处理器。它的工作方式类似于地图缩减架构。它将输入映射到不同的处理器,并收集所有处理器的输出。执行代码后,它以列表或数组的形式返回输出。它等待所有任务完成,然后返回输出。执行中的进程存储在存储器中,而其他非执行进程则存储在存储器之外。
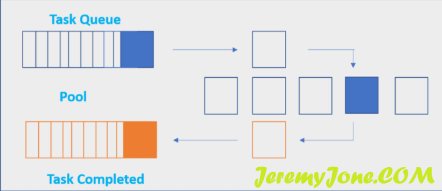
由于这些Pool方法都使用一个Queue将任务传递给工作进程,所有东西在Queue中必须是可选的,但是一开始,我的私有函数__opFunc定义在内部,是不可选的,因为它没有在模块的顶层定义。
所以,如果使用Pool,那么它的传入函数必须是顶级函数,这样才会被Queue使用。
至此,可以愉快地使用进程池了~

文章评论